Linux 问题总结
Linux 问题总结
crond文件权限的坑
crond第一次加载的时候(刚启动)会去检查文件属性,不是644的话以后都不会执行了,即使后面chmod改成了644.
手工随便修改一下该文件的内容就能触发自动执行了,或者重启crond, 或者 sudo service crond reload, 或者 /etc/cron.d/下有任何修改都会触发crond reload配置(包含 touch )。
总之 crond会每分钟去检查job有没有change,有的话才触发reload,这个change看的时候change time有没有变化,不看权限的变化,仅仅是权限的变化不会触发crond reload。
crond会每分钟去检查一下job有没有修改,有修改的话会reload,但是这个修改不包含权限的修改。可以简单地理解这个修改是指文件的change time。
cgroup目录报No space left on device
可能是因为某个规则下的 cpuset.cpus 文件是空导致的
容器中root用户执行 su - admin 切换失败
问题原因:https://access.redhat.com/solutions/30316
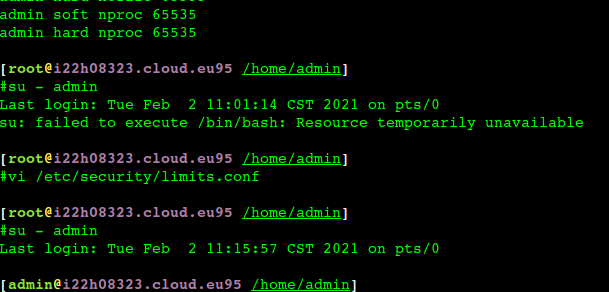
如上图去掉 admin nproc限制就可以了
这是因为root用户的nproc是unlimited,但是admin的是65535,所以切不过去
1 | [root@i22h08323 /home/admin] |
容器中ulimit限制了sudo的执行
容器启动的时候默认nofile为65535(可以通过 docker run –ulimit nofile=655360 来设置),如果容器中的 /etc/security/limits.conf 中设置的nofile大于 65535就会报错,因为容器的1号进程就是65535了,比如在容器中用root用户执行sudo ls报错:
1 | #sudo ls |
可以修改容器中的 ulimit 不要超过默认的65535或者修改容器的启动参数来解决。
子进程都会继承父进程的一些环境变量,比如 limits.conf, sudo/su/crond/passwd等都会触发重新加载limits,
1 | grep -rin pam_limit /etc/pam.d //可以看到触发重新加载的场景 |
systemd limits
/etc/security/limits.conf 的配置,只适用于通过PAM 认证登录用户的资源限制,它对systemd 的service 的资源限制不生效。
因此登录用户的限制,通过/etc/security/limits.conf 与/etc/security/limits.d 下的文件设置即可。
对于systemd service 的资源设置,则需修改全局配置,全局配置文件放在/etc/systemd/system.conf 和/etc/systemd/user.conf,同时也会加载两个对应目录中的所有.conf 文件/etc/systemd/system.conf.d/.conf 和/etc/systemd/user.conf.d/.conf。
open files 限制在1024
docker 容器内 nofile只有1024,检查:
1 | cat /etc/sysconfig/docker |
关于ulimit的一些知识点
参考 Ulimit http://blog.yufeng.info/archives/2568
- limit的设定值是 per-process 的
- 在 Linux 中,每个普通进程可以调用 getrlimit() 来查看自己的 limits,也可以调用 setrlimit() 来改变自身的 soft limits
- 要改变 hard limit, 则需要进程有 CAP_SYS_RESOURCE 权限
- 进程 fork() 出来的子进程,会继承父进程的 limits 设定
ulimit是 shell 的内置命令。在执行ulimit命令时,其实是 shell 自身调用 getrlimit()/setrlimit() 来获取/改变自身的 limits. 当我们在 shell 中执行应用程序时,相应的进程就会继承当前 shell 的 limits 设定- shell 的初始 limits 通常是 pam_limits 设定的。顾名思义,pam_limits 是一个 PAM 模块,用户登录后,pam_limits 会给用户的 shell 设定在 limits.conf 定义的值
ulimit, limits.conf 和 pam_limits模块 的关系,大致是这样的:
- 用户进行登录,触发 pam_limits;
- pam_limits 读取 limits.conf,相应地设定用户所获得的 shell 的 limits;
- 用户在 shell 中,可以通过 ulimit 命令,查看或者修改当前 shell 的 limits;
- 当用户在 shell 中执行程序时,该程序进程会继承 shell 的 limits 值。于是,limits 在进程中生效了
判断要分配的句柄号是不是超过了 limits.conf 中 nofile 的限制。fd 是当前进程相关的,是一个从 0 开始的整数
结论1:soft nofile 和 fs.nr_open的作用一样,它两都是限制的单个进程的最大文件数量。区别是 soft nofile 可以按用户来配置,而 fs.nr_open 所有用户只能配一个。注意 hard nofile 一定要比 fs.nr_open 要小,否则可能导致用户无法登陆。
结论2:fs.file-max: 整个系统上可打开的最大文件数,但不限制 root 用户
pam 权限报错
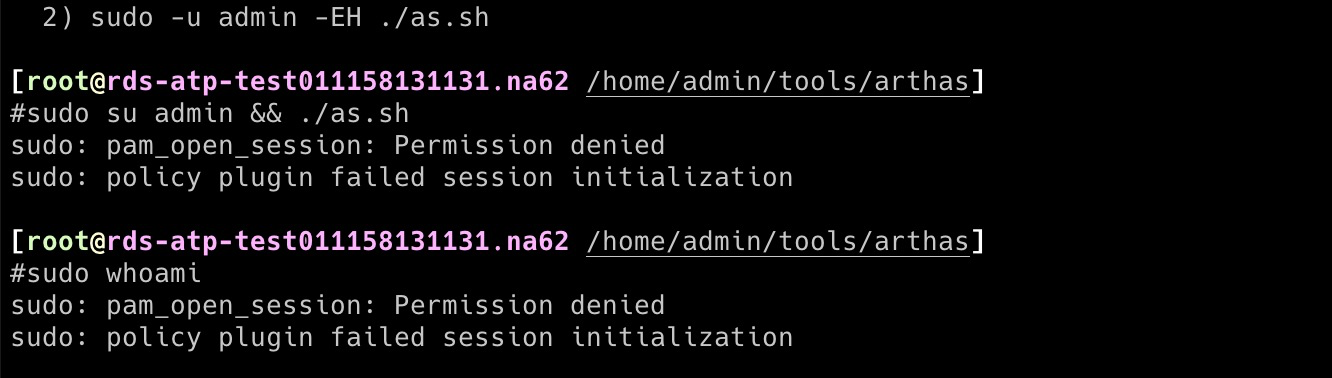
从debug信息看如果是pam权限报错的话,需要将 required 改成 sufficient
1 | $cat /etc/pam.d/crond |
PAM 提供四个安全领域的特性,但是应用程序不太可能同时需要所有这些方面。例如,passwd 命令只需要下面列表中的第三组:
account处理账户限制。对于有效的用户,允许他做什么?auth处理用户识别 — 例如,通过输入用户名和密码。password只处理与密码相关的问题,比如设置新密码。session处理连接管理,包括日志记录。
在 /etc/pam.d 目录中为将使用 PAM 的每个应用程序创建一个配置文件,文件名与应用程序名相同。例如,login 命令的配置文件是 /etc/pam.d/login。
必须定义将应用哪些模块,创建一个动作 “堆”。PAM 运行堆中的所有模块,根据它们的结果允许或拒绝用户的请求。还必须定义检查是否是必需的。最后,other 文件为没有特殊规则的所有应用程序提供默认规则。
optional模块可以成功,也可以失败;PAM 根据模块是否最终成功返回success或failure。required模块必须成功。如果失败,PAM 返回failure,但是会在运行堆中的其他模块之后返回。requisite模块也必须成功。但是,如果失败,PAM 立即返回failure,不再运行其他模块。sufficient模块在成功时导致 PAM 立即返回success,不再运行其他模块。
当pam安装之后有两大部分:在/lib64/security目录下的各种pam模块以及/etc/pam.d和/etc/pam.d目录下的针对各种服务和应用已经定义好的pam配置文件。当某一个有认证需求的应用程序需要验证的时候,一般在应用程序中就会定义负责对其认证的PAM配置文件。以vsftpd为例,在它的配置文件/etc/vsftpd/vsftpd.conf中就有这样一行定义:
pam_service_name=vsftpd
表示登录FTP服务器的时候进行认证是根据/etc/pam.d/vsftpd文件定义的内容进行。
PAM 认证过程
当程序需要认证的时候已经找到相关的pam配置文件,认证过程是如何进行的?下面我们将通过解读/etc/pam.d/system-auth文件予以说明。
首先要声明一点的是:system-auth是一个非常重要的pam配置文件,主要负责用户登录系统的认证工作。而且该文件不仅仅只是负责用户登录系统认证,其它的程序和服务通过include接口也可以调用到它,从而节省了很多重新自定义配置的工作。所以应该说该文件是系统安全的总开关和核心的pam配置文件。
下面是/etc/pam.d/system-auth文件的全部内容:
1 | $cat /etc/pam.d/system-auth |
第一部分
当用户登录的时候,首先会通过auth类接口对用户身份进行识别和密码认证。所以在该过程中验证会经过几个带auth的配置项。
其中的第一步是通过pam_env.so模块来定义用户登录之后的环境变量, pam_env.so允许设置和更改用户登录时候的环境变量,默认情况下,若没有特别指定配置文件,将依据/etc/security/pam_env.conf进行用户登录之后环境变量的设置。
然后通过pam_unix.so模块来提示用户输入密码,并将用户密码与/etc/shadow中记录的密码信息进行对比,如果密码比对结果正确则允许用户登录,而且该配置项的使用的是“sufficient”控制位,即表示只要该配置项的验证通过,用户即可完全通过认证而不用再去走下面的认证项。不过在特殊情况下,用户允许使用空密码登录系统,例如当将某个用户在/etc/shadow中的密码字段删除之后,该用户可以只输入用户名直接登录系统。
下面的配置项中,通过pam_succeed_if.so对用户的登录条件做一些限制,表示允许uid大于500的用户在通过密码验证的情况下登录,在Linux系统中,一般系统用户的uid都在500之内,所以该项即表示允许使用useradd命令以及默认选项建立的普通用户直接由本地控制台登录系统。
最后通过pam_deny.so模块对所有不满足上述任意条件的登录请求直接拒绝,pam_deny.so是一个特殊的模块,该模块返回值永远为否,类似于大多数安全机制的配置准则,在所有认证规则走完之后,对不匹配任何规则的请求直接拒绝。
第二部分
三个配置项主要表示通过account账户类接口来识别账户的合法性以及登录权限。
第一行仍然使用pam_unix.so模块来声明用户需要通过密码认证。第二行承认了系统中uid小于500的系统用户的合法性。之后对所有类型的用户登录请求都开放控制台。
第三部分
会通过password口令类接口来确认用户使用的密码或者口令的合法性。第一行配置项表示需要的情况下将调用pam_cracklib来验证用户密码复杂度。如果用户输入密码不满足复杂度要求或者密码错,最多将在三次这种错误之后直接返回密码错误的提示,否则期间任何一次正确的密码验证都允许登录。需要指出的是,pam_cracklib.so是一个常用的控制密码复杂度的pam模块,关于其用法举例我们会在之后详细介绍。之后带pam_unix.so和pam_deny.so的两行配置项的意思与之前类似。都表示需要通过密码认证并对不符合上述任何配置项要求的登录请求直接予以拒绝。不过用户如果执行的操作是单纯的登录,则这部分配置是不起作用的。
第四部分
主要将通过session会话类接口为用户初始化会话连接。其中几个比较重要的地方包括,使用pam_keyinit.so表示当用户登录的时候为其建立相应的密钥环,并在用户登出的时候予以撤销。不过该行配置的控制位使用的是optional,表示这并非必要条件。之后通过pam_limits.so限制用户登录时的会话连接资源,相关pam_limit.so配置文件是/etc/security/limits.conf,默认情况下对每个登录用户都没有限制。关于该模块的配置方法在后面也会详细介绍。
常用的PAM模块介绍
| PAM模块 | 结合管理类型 | 说明 |
|---|---|---|
| pam_unix.so | auth | 提示用户输入密码,并与/etc/shadow文件相比对.匹配返回0 |
| pam_unix.so | account | 检查用户的账号信息(包括是否过期等).帐号可用时,返回0. |
| pam_unix.so | password | 修改用户的密码. 将用户输入的密码,作为用户的新密码更新shadow文件 |
| pam_shells.so | auth、account | 如果用户想登录系统,那么它的shell必须是在/etc/shells文件中之一的shell |
| pam_deny.so | account、auth、password、session | 该模块可用于拒绝访问 |
| pam_permit.so | account、auth、password、session | 模块任何时候都返回成功. |
| pam_securetty.so | auth | 如果用户要以root登录时,则登录的tty必须在/etc/securetty之中. |
| pam_listfile.so | account、auth、password、session | 访问应用程的控制开关 |
| pam_cracklib.so | password | 这个模块可以插入到一个程序的密码栈中,用于检查密码的强度. |
| pam_limits.so | session | 定义使用系统资源的上限,root用户也会受此限制,可以通过/etc/security/limits.conf或/etc/security/limits.d/*.conf来设定 |
debug crond
先停掉 crond service,然后开启debug参数
1 | systemctl stop crond |
或者增加更多的debug信息, debug sudo/sudoers , 在 /etc/sudo.conf 中增加了:
1 | Debug sudo /var/log/sudo_debug all@warn |
crond ERROR (getpwnam() failed)
1 | crond[246590]: (/usr/bin/ssh) ERROR (getpwnam() failed) |
要特别注意crond格式是 时间 用户 命令
有时候我们可以省略用户,但是在 /etc/cron.d/ 中省略用户后报错如上
进程和线程
把进程看做是资源分配的单位,把线程才看成一个具体的执行实体。
deleted 文件
lsof +L1 或者 lsof | grep delete 发现有被删除的文件,且占用大量磁盘空间
lsof /path/file 列出打开文件的进程,也可以是路径,还可以通过参数 “+D” 来递归路径
清理:
1 | 先通过 lsof +L1 找到 deleted 文件以及 pid |
No route to host
如果ping ip能通,但是curl/telnet 访问 ip+port 报not route to host 错误,这肯定不是route问题(因为ping能通), 一般都是目标机器防火墙的问题
可以停掉防火墙验证,或者添加端口到防火墙:
1 | #firewall-cmd --permanent --add-port=8090/tcp |
强制重启系统

hostname
hostname -i 是根据机器的hostname去解析ip,如果 /etc/hosts里面没有指定hostname对应的ip就会走dns 流程然后libnss_myhostname 返回所有ip
getHostName获取的机器名如果对应的ip不是127.0.0.1,那么就用这个ip,否则就需要通过getHostByName获取所有网卡选择一个
tsar Floating point execption
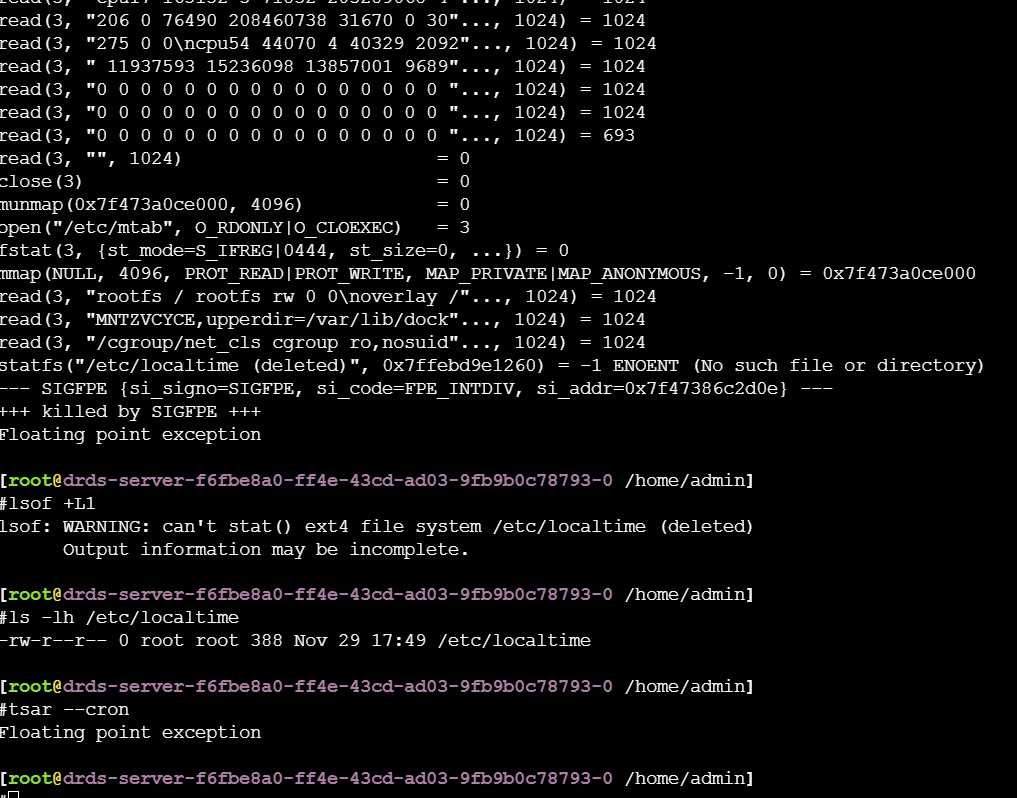
因为 /etc/localtime 是deleted状态
奇怪的文件大小 sparse file
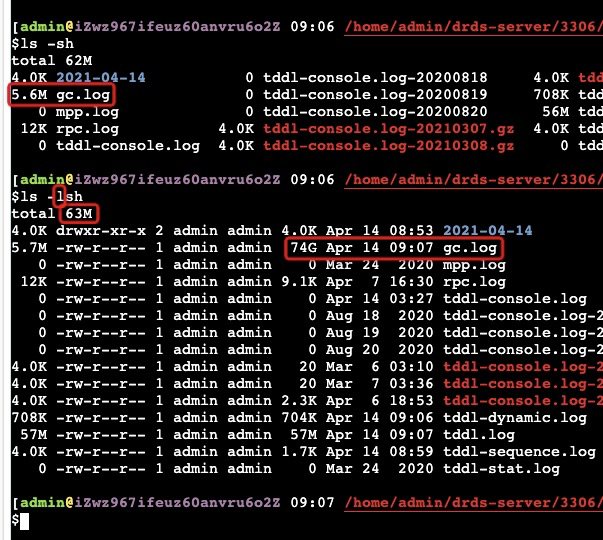
如上图 gc.log 实际为5.6M,但是通过 ls -lh 就变成74G了,但实际上总文件夹才63M。因为写文件的时候lseek了74G的地方写入5.6M的内容就看到是这个样子了,而前面lseek的74G是不需要从磁盘上分配出来的.
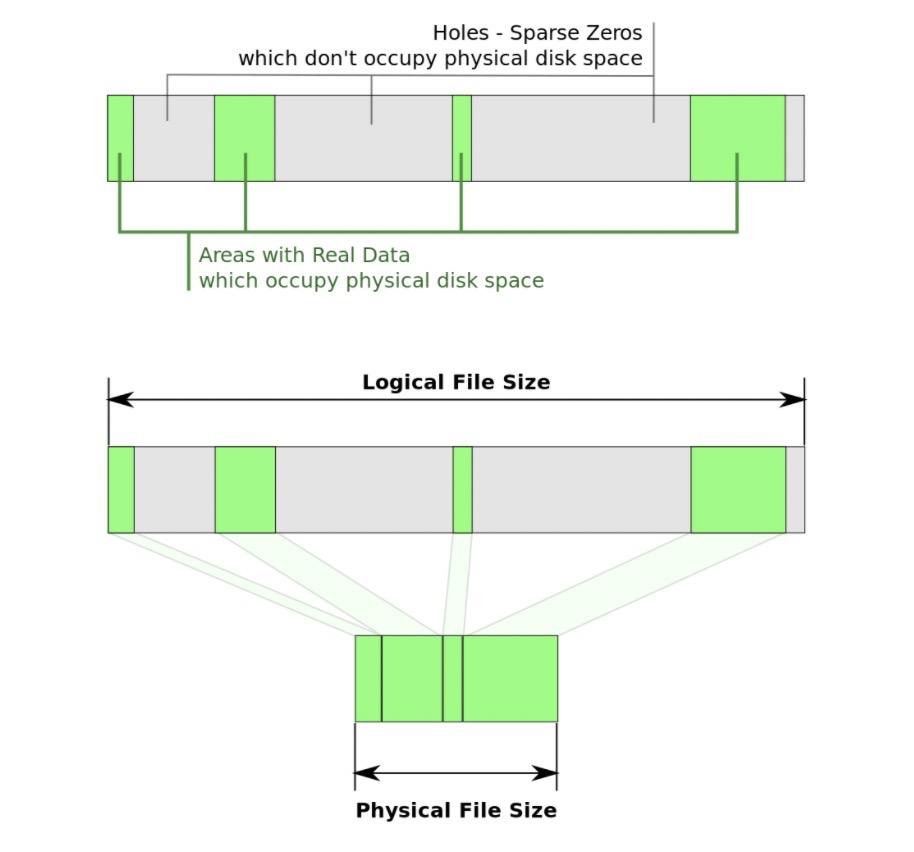
回收文件中的空洞:sudo fallocate -c –length 70G gc.log
如果文件一直打开写入中是没法回收的,因为一回收又被重新lseek到之前的末尾重新写入了!
增加dmesg buffer
If dmesg does not show any information about NUMA, then increase the Ring Buffer size:
Boot with ‘log_buf_len=16M’ (or some other big value). Refer the following kbase article How do I increase the kernel log ring buffer size? for steps on how to increase the ring buffer
yum 源问题处理
Yum commands error “pycurl.so: undefined symbol”
1 | # yum check update |
- Check and fix the related library paths or remove 3rd party libraries, usually
libcurlorlibssh2. On a x86_64 system, the standard paths for those libraries are/usr/lib64/libcurl.so.4and/usr/lib64/libssh2.so.1
软中断、系统调用和上下文切换
“你可以把内核看做是不断对请求进行响应的服务器,这些请求可能来自在CPU上执行的进程,也可能来自发出中断的外部设备。老板的请求相当于中断,而顾客的请求相当于用户态进程发出的系统调用”。
软中断和系统调用一样,都是CPU停止掉当前用户态上下文,保存工作现场,然后陷入到内核态继续工作。二者的唯一区别是系统调用是切换到同进程的内核态上下文,而软中断是则是切换到了另外一个内核进程ksoftirqd上。
系统调用开销是200ns起步
从实验数据来看,一次软中断CPU开销大约3.4us左右
实验结果显示进程上下文切换平均耗时 3.5us,lmbench工具显示的进程上下文切换耗时从2.7us到5.48之间
大约每次线程切换开销大约是3.8us左右。从上下文切换的耗时上来看,Linux线程(轻量级进程)其实和进程差别不太大。
软中断和进程上下文切换比较起来,进程上下文切换是从用户进程A切换到了用户进程B。而软中断切换是从用户进程A切换到了内核线程ksoftirqd上。而ksoftirqd作为一个内核控制路径,其处理程序比一个用户进程要轻量,所以上下文切换开销相对比进程切换要少一些(实际数据基本差不多)。
系统调用只是在进程内将用户态切换到内核态,然后再切回来,而上下文切换可是直接从进程A切换到了进程B。显然这个上下文切换需要完成的工作量更大。
软中断开销计算
- 查看软中断总耗时, 首先用top命令可以看出每个核上软中断的开销占比,是在si列(1.2%–1秒[1000ms]中的1.2%)
- 查看软中断次数,再用vmstat命令可以看到软中断的次数(in列 56000)
- 计算每次软中断的耗时,该机器是16核的物理实机,故可以得出每个软中断需要的CPU时间是=12ms/(56000/16)次=3.428us。从实验数据来看,一次软中断CPU开销大约3.4us左右
Linux 启动进入紧急模式
可能是因为磁盘挂载不上,检查 /etc/fstab 中需要挂载的磁盘,尝试 mount -a 是否能全部挂载,麒麟下容易出现弄丢磁盘的标签和uuid
否则的话debug为啥,比如检查设备标签(e2label)是否冲突之类的
进程状态
https://zhuanlan.zhihu.com/p/401910162
1 | PROCESS STATE CODES |
D状态的进程
Process D是指进程处于不可中断状态。即uninterruptible sleep,通常我们比较常遇到的就是进程自旋等到进入竞争区等,刷脏页,进程同步等
D: Disk sleep(task_uninterruptible)–比如,磁盘满,导致进程D,无法kill
相关设置
1 | echo 1 > /proc/sys/kernel/hung_task_panic |
这个参数可以用来处理 D 状态进程
内核在 3.10.0 版本之后提供了 hung task 机制,用来检测系统中长期处于 D 状体的进程,如果存在,则打印相关警告和进程堆栈。
如果配置了 hung_task_panic ,则会直接发起 panic 操作,然后结合 kdump 可以搜集到相关的 vmcore 文件,用于定位分析。
其基本原理也很简单,系统启动时会创建一个内核线程 khungtaskd,定期遍历系统中的所有进程,检查是否存在处于 D 状态且超过 120s 的进程,如果存在,则打印相关警告和进程堆栈,并根据参数配置决定是否发起 panic 操作。
查看D进程出现的原因:

这个堆栈能看到进程在哪里 D 住了,但不一定是根本原因,有可能是被动进入 D 状态的

T 状态进程
kill -CONT pid 来恢复
jmap -heap/histo和大家使用-F参数是一样的,底层都是通过serviceability agent来实现的,并不是jvm attach的方式,通过sa连上去之后会挂起进程,在serviceability agent里存在bug可能导致detach的动作不会被执行,从而会让进程一直挂着,可以通过top命令验证进程是否处于T状态,如果是说明进程被挂起了,如果进程被挂起了,可以通过kill -CONT [pid]来恢复。
路由
『你所规划的路由必须要是你的网卡 (如 eth0) 或 IP 可以直接沟通 (broadcast) 的情况』才行
1 | $sudo route add -net 11.164.191.0 gw 11.164.191.247 netmask 255.255.255.0 bond0 |
linux 2.6.32内核高精度定时器带来的cpu sy暴涨的“问题”
在 2.6.32 以前的内核里,即使你在java里写queue.await(1ns)之类的代码,其实都是需要1ms左右才会执行的,但.32以后则可以支持ns级的调度,对于实时性要求非常非常高的性能而言,这本来是个好特性。
1 | cat /proc/timer_list | grep .resolution |
可以通过在 /boot/grub2/grub.cfg 中相应的kernel行的最后增加highres=off nohz=off来关闭高精度(不建议这样做,最好还是程序本身做相应的修改)
后台执行
将任务放到后台,断开ssh后还能运行:
- “ctrl-Z”将当前任务挂起;
- “disown -h”让该任务忽略 SIGHUP 信号(不会因为掉线而终止执行);
- “bg”让该任务在后台恢复运行。
Linux 进程调度
Linux的进程调度有一个不太为人熟知的特性,叫做wakeup affinity,它的初衷是这样的:如果两个进程频繁互动,那么它们很有可能共享同样的数据,把它们放到亲缘性更近的scheduling domain有助于提高缓存和内存的访问性能,所以当一个进程唤醒另一个的时候,被唤醒的进程可能会被放到相同的CPU core或者相同的NUMA节点上。
这个特性缺省是打开的,它有时候很有用,但有时候却对性能有伤害作用。设想这样一个应用场景:一个主进程给成百上千个辅进程派发任务,这成百上千个辅进程被唤醒后被安排到与主进程相同的CPU core或者NUMA节点上,就会导致负载严重失衡,CPU忙的忙死、闲的闲死,造成性能下降。https://mp.weixin.qq.com/s/DG1v8cUjcXpa0x2uvrRytA
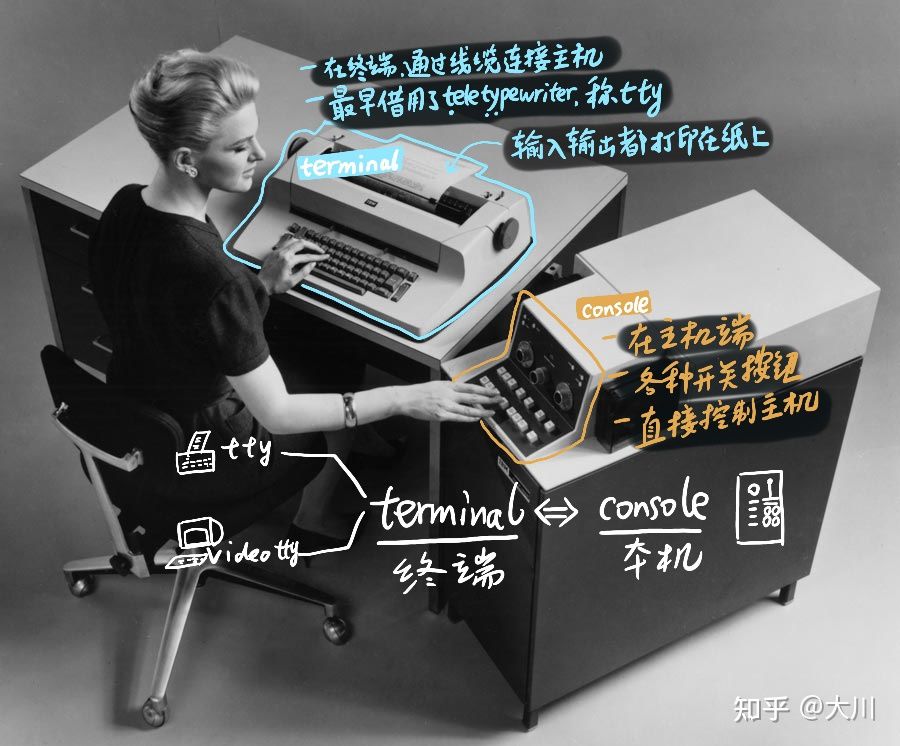
tty
tty(teletype–最早的一种终端设备,远程打字机) stty 设置tty的相关参数
tty都在 /dev 下,通过 ps -ax 可以看到进程的tty;通过tty 可以看到本次的终端
/dev/pty(Pseudo Terminal) 伪终端
/dev/tty 控制终端
远古时代tty是物理形态的存在
PC时代,物理上的terminal已经没有了(用虚拟的伪终端代替,pseudo tty, 简称pty),相对kernel增加了shell,这是terminal和shell容易混淆,他们的含义
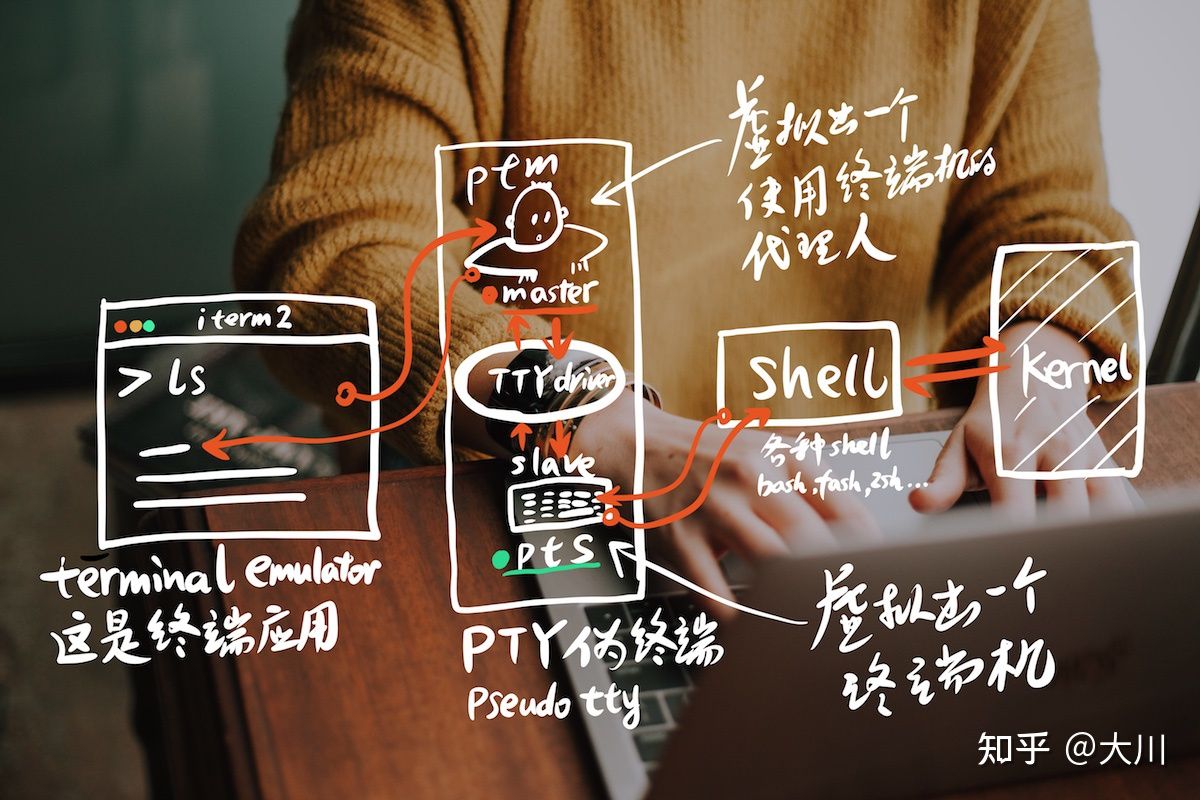
实际像如下图的工作协作:
rsync
1 | 将本地yum备份到150上的/data/yum/ 下 |
-a、--archive参数表示存档模式,保存所有的元数据,比如修改时间(modification time)、权限、所有者等,并且软链接也会同步过去。
--delete参数删除只存在于目标目录、不存在于源目标的文件,即保证目标目录是源目标的镜像。
-i参数表示输出源目录与目标目录之间文件差异的详细情况。
--link-dest参数指定增量备份的基准目录。
-n参数或--dry-run参数模拟将要执行的操作,而并不真的执行。配合-v参数使用,可以看到哪些内容会被同步过去。
--partial参数允许恢复中断的传输。不使用该参数时,rsync会删除传输到一半被打断的文件;使用该参数后,传输到一半的文件也会同步到目标目录,下次同步时再恢复中断的传输。一般需要与--append或--append-verify配合使用。
--progress参数表示显示进展。
-r参数表示递归,即包含子目录。
-v参数表示输出细节。-vv表示输出更详细的信息,-vvv表示输出最详细的信息。
Shebang
Shebang 的东西 #!/bin/bash
对 Shebang 的处理是内核在进行。当内核加载一个文件时,会首先读取文件的前 128 个字节,根据这 128 个字节判断文件的类型,然后调用相应的加载器来加载。
ELF(Executable and Linkable Format)
对应windows下的exe
修改启动参数
1 | $cat change_kernel_parameter.sh |
制作启动盘
Windows 上用 UltraISO 烧制,Mac 上就比较简单了,直接用 dd 就可以搞
1 | $ diskutil list |
1 | umount /dev/sdn1 |
性能
为保证服务性能应选用 performance 模式,将 CPU 频率固定工作在其支持的最高运行频率上,不进行动态调节,操作命令为 cpupower frequency-set --governor performance。
常用命令
- dmesg | tail
- vmstat 1
- mpstat -P ALL 1
- pidstat 1
- iostat -xz 1
- free -m
- sar -n DEV 1
- sar -n TCP,ETCP 1
案例
1 | //检查sda磁盘中哪个应用程序占用的io比较高 |
内存——虚拟内存参数
dirty_ratio百分比值。当脏的 page cache 总量达到系统内存总量的这一百分比后,系统将开始使用 pdflush 操作将脏的 page cache 写入磁盘。默认值为 20%,通常不需调整。对于高性能 SSD,比如 NVMe 设备来说,降低其值有利于提高内存回收时的效率。dirty_background_ratio百分比值。当脏的 page cache 总量达到系统内存总量的这一百分比后,系统开始在后台将脏的 page cache 写入磁盘。默认值为 10%,通常不需调整。对于高性能 SSD,比如 NVMe 设备来说,设置较低的值有利于提高内存回收时的效率。
I/O 调度器
I/O 调度程序确定 I/O 操作何时在存储设备上运行以及持续多长时间。也称为 I/O 升降机。对于 SSD 设备,宜设置为 noop。
1 | echo noop > /sys/block/${SSD_DEV_NAME}/queue/scheduler |
磁盘挂载参数
noatime 读取文件时,将禁用对元数据的更新。它还启用了 nodiratime 行为,该行为会在读取目录时禁用对元数据的更新。
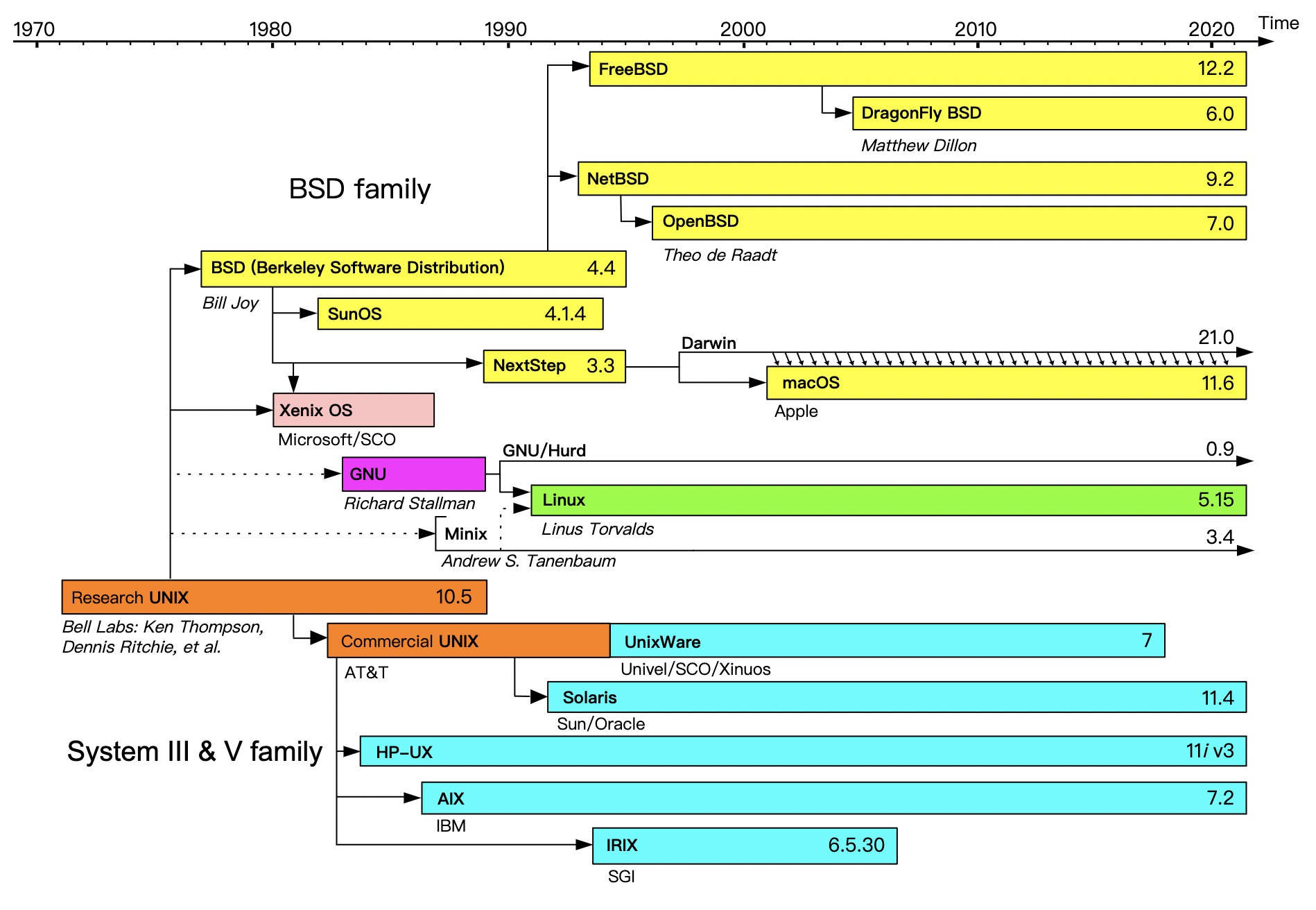
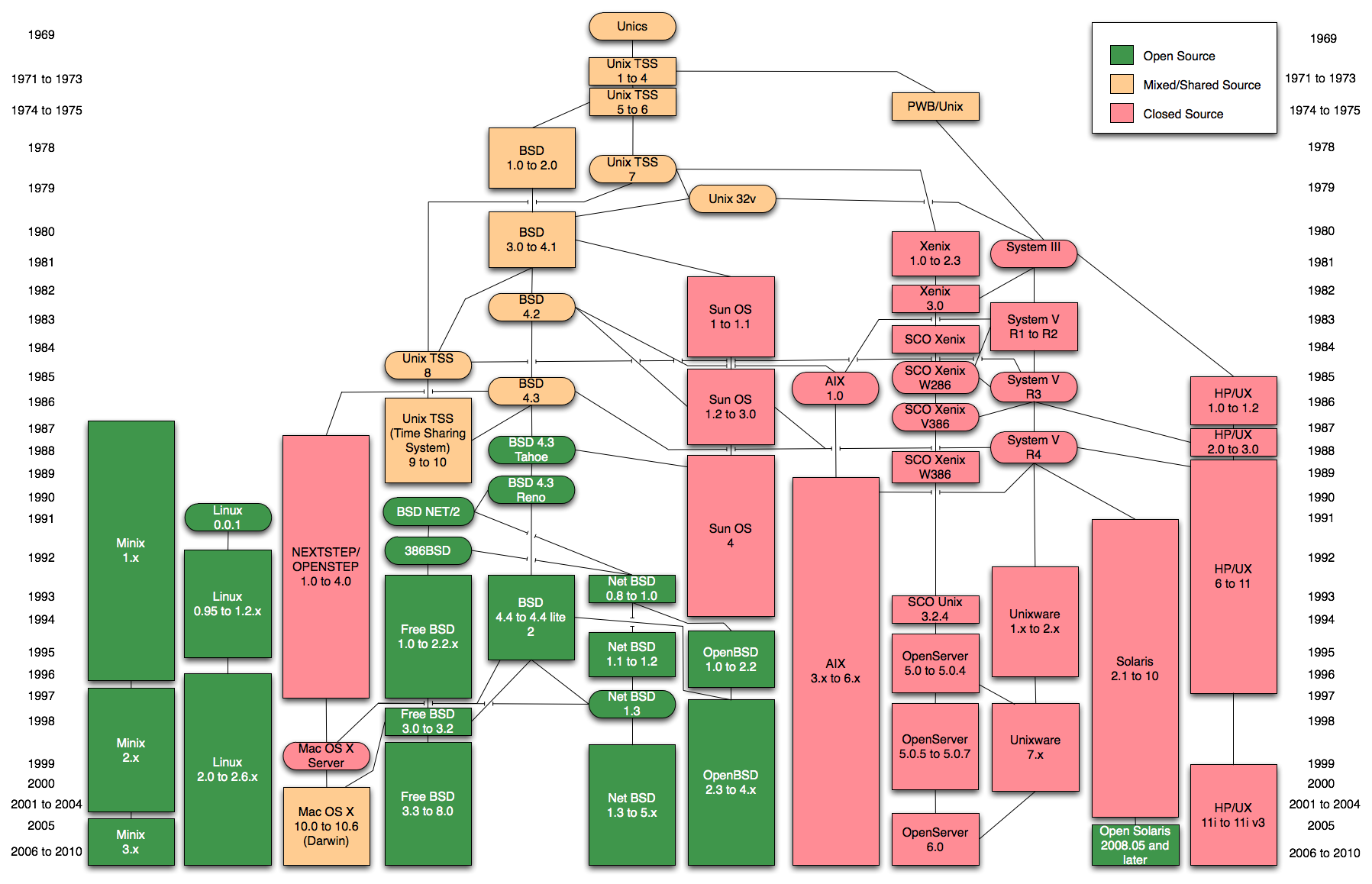
Unix Linux关系
linux 发行版关系
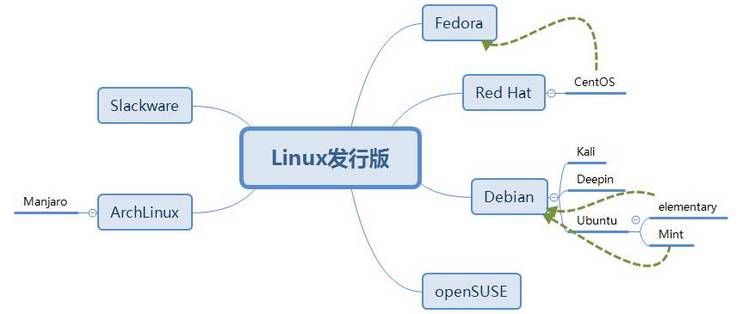
Fedora:基于Red Hat Linux,在Red Hat Linux终止发行后,红帽公司计划以Fedora来取代Red Hat Linux在个人领域的应用,而另外发行的Red Hat Enterprise Linux取代Red Hat Linux在商业应用的领域。Fedora的功能对于用户而言,它是一套功能完备、更新快速的免费操作系统,而对赞助者Red Hat公司而言,它是许多新技术的测试平台,被认为可用的技术最终会加入到Red Hat Enterprise Linux中。Fedora大约每六个月发布新版本。
不同发行版几乎采用了不同包管理器(SLES、Fedora、openSUSE、centos、RHEL使用rmp包管理系统,包文件以RPM为扩展名;Ubuntu系列,Debian系列使用基于DPKG包管理系统,包文件以deb为扩展名。)
69年Unix诞生在贝尔实验室,80年 DARPA(国防部高级计划局)请人在Unix实现全新的TCP、IP协议栈。ARPANET最先搞出以太网
Linux 从91年到95年处于成长期,真正大规模应用是Linux+Apache提供的WEB服务被大家大规模采用
rpm: centos/fedora/suse
deb: debian/ubuntu/uos(早期基于ubuntu定制,后来基于debian定制,再到最近开始直接基于kernel定制)
ARPANET:高等研究計劃署網路(英語:Advanced Research Projects Agency Network),通称阿帕网(英語:ARPANET)是美國國防高等研究計劃署开发的世界上第一个运营的封包交换网络,是全球互联网的鼻祖。
TCP/IP:1974年,卡恩和瑟夫带着研究成果,在IEEE期刊上,发表了一篇题为《关于分组交换的网络通信协议》的论文,正式提出TCP/IP,用以实现计算机网络之间的互联。
在1983年,美国国防部高级研究计划局决定淘汰NCP协议(ARPANET最早使用的协议),TCP/IP取而代之。
Deepin UOS
*Deepin 与统信 UOS 类似于红帽的 Fedora 与 RHEL 的上下游关系,Deepin 依然保持着原来的社区运营模式,而统信 UOS 则是基于社区版 Deepin 构建的商业发行版,为 Deepin 挖掘更多的商业机会和更大的商业价值,进而反哺社区,形成良性循环*。
参考文章
https://www.cnblogs.com/kevingrace/p/8671964.html
https://www.jianshu.com/p/ac3e7009a764
B 站哈工大操作系统视频地址:https://www.bilibili.com/video/BV1d4411v7u7?from=search&seid=2361361014547524697
B 站清华大学操作系统视频地址:https://www.bilibili.com/video/BV1js411b7vg?from=search&seid=2361361014547524697